Developing Statically Typed Programming Language
Edit · Aug 5, 2017 · 22 minutes read · Follow @mgechev
In this blog post we’ll go through a sample implementation of a type checker, interpreter and a transpiler for a basic purely functional programming language, which is based on the lambda calculus. We will do a “full-stack” programming language development by going through formal definition of the language’s syntax, semantics and type system. After that we’ll demonstrate how we can “translate” these definitions to JavaScript.
Although the article doesn’t require any mathematical background, it’ll be useful to have high-level understanding of how compilers work. The article is inspired by the book “Types and Programming Languages”.
The source code of the implementation can be found at my GitHub profile.
Syntax
The syntax of the language is going to be quite simple.

Our programs will belong to the language defined by the following grammar:
t ::=
x # variable
λ x: T → t # called an abstraction by lambda calculus. In JavaScript we call it a function.
t t # application
true # true literal
false # false literal
if t then t else t # conditional expression
succ t # returns the next natural number when applied to `t`
prev t # returns the previous natural number when applied to `t`
iszero t # returns `true` if the argument after evaluation equals `0`, otherwise `false`
0 # symbol representing the natural number zero
The abstraction nonterminal allows us to declare functions with only one argument of type T and an expression t as a body. The syntax of the abstractions involves the unicode symbols → and λ . In case you have a Greek keyboard layout λ will be easy to type, however, in order to quickly type → you will need some kind of a keyboard shortcut. In other words, the syntax of our language is not very ergonomic.
Note that there’s no syntax construct for expressing negative numbers and on top of that succ and pred produce natural numbers. In order to be consistent with the grammar the result of pred 0 will be 0.
Regarding the type system, we will have two primitive types:
T ::= Nat | Bool
Notice that in contrast to other statically typed programming languages, such as Haskell or Elm, we do not have a syntactical construct for declaring the type of a function. In Haskell the semantics of the annotation T1 → T2 is a function which accepts one argument of type T1 and returns result of type T2. In our grammar, we do not have this explicit type annotation because we’re going to apply type inference in order to guess a function’s type based on the type of its argument and body.
Playground
Now after we’re familiar with the syntax, we can try to write some code. In the textarea below enter your program and click on the button “Evaluate” to see the result:
Semantics
Before going any further, lets show a few sample programs belonging to the programming language that we’re going to develop.

(λ a: Nat → succ succ a) 0
In the example above we declare an anonymous function which accepts a single argument called a of type Nat. In the body of the function we apply twice the predefined function succ to a. The anonymous function we apply to 0. This is going to produce 2 as final result.
The equivalent of this program in JavaScript will be:
(a => succ(succ(a)))(0)
Where succ is defined as:
const succ = a => a + 1
A more complicated program in our programming language will look like this:
(
λ f: Nat →
(λ g: Nat → f) 0
) (succ 0)
Lets explain the evaluation step by step:
-
Reduce the expression with left side
(λ f: Nat → (λ g: Nat → f) 0)and right side(succ 0).( λ f: Nat → (λ g: Nat → f) 0 ) (succ 0) -
Substitute
gwith0(apply beta reduction) in the expression(λ f: Nat → (λ g: Nat → f) 0)and get(λ f: Nat → f).( λ f: Nat → f ) (succ 0) -
Increment
0in the expressionsucc 0and pass the result to(λ f: Nat → f).( λ f: Nat → f ) 1 -
Return result.
1
Formally, we can show the small-step semantics of our language in the following way:
Small-step semantics
In this section we’ll take a look at the small-step semantics of the language.
Lets suppose σ is the current state of our program, which keeps what value each individual variable has.
Variables
1)
─────────────
(x, σ) → σ(x)
1) simply means that for variable x we return its value kept in the state σ.
Built-in functions
The built-in functions in our language are succ, pred and iszero. Here’s the small-step semantics of succ and pred:
1)
t1 → t2
─────────────────
succ t1 → succ t2
2)
pred 0 → 0
3)
pred succ v → v
4)
t1 → t2
─────────────────
pred t1 → pred t2
1) simply means that if expression t1, passed to succ evaluates to t2, succ evaluates to succ t2.
2) we define that the result of pred 0 equals 0 in order to keep the language consistent and disallow negative numbers not only syntactically but also as result of evaluation.
We’re going to define iszero the following way:
1)
iszero 0 → true
2)
iszero succ v → false
3)
t1 → t2
────────────────────
iszero t1 → iszero t2
This means that iszero applied to 0 returns true (by 1)). The result of the evaluation of iszero applied to any other number greater than 0 will equal false (by 2)). If t1 evaluates to t2, then iszero t1 equals the result of the evaluation iszero t2 (by 3)).
Conditional expressions
Lets take a look at the small-step semantics for the conditional expressions:
1)
if true then t2 else t3 → t2
if false then t2 else t3 → t3
If the condition of the conditional expression is true then we return the expression from the then part, otherwise, we return the one from the else part.
2)
t1 → v
─────────────────────────────────────────────
if t1 then t2 else t3 → if v then t2 else t3
If given expression t1 evaluates to v and this expression is passed as condition of the conditional expression, the evaluation of the conditional expression is equivalent to the evaluation of the conditional expression with v passed as condition.
Abstraction & Application
In this section we’ll explain the function evaluation.
1)
(λ x: T → t) v → { x → v } t
2)
t1 → v
────────────
t1 t2 → v t2
3)
t2 → v
────────────
v1 t2 → t1 v
1) means that if we have the abstraction (λ x: T → t), where T is the type of x, and apply it to v, we need to substitute all the occurrences of x in t with v.
In 2) if t1 evaluates to v, t1 t2 evaluates to v applied to t2.
The semantics of 3) is that if t2 evaluates to v, v1 t2 evaluates to t1 applied to v.
Type System

Although the small-step semantics laws above are quite descriptive and by using them we already can build an evaluator for our programming language, we still can construct some ridiculous programs. For instance the following program is a valid according to the grammar from the “Syntax” section above but is semantically incorrect:
if 1 then true else 2
The condition of the conditional expression is expected to be of type boolean, however, we pass a natural number. Another problem with the snippet is that the result of both branches of the expression should return result with the same type but this is not the case in our example.
In order to handle such invalid programs we can introduce a mechanism of program verification through type checking. This way, we will assign types to the individual constructs and as part of the compilation process, verify if the program is valid according to the “contract signed” with the type annotations.
Notice that the type checking will be performed compile-time. The alternative is to perform runtime type checking, which will not prevent us from distributing invalid programs.
An interesting question is if the type system is sound and complete. If the system is sound it should prevent false negatives (i.e. should reject all invalid programs), however, it may also reject valid programs. In order to make sure the type system prevents false positives, it should also be complete.
Type Rules
Lets define that:
true : Bool
false : Bool
n : Nat, n ∈ ℕ
Based on the types of our terminals, lets declare the type rules for succ, pred, iszero and the conditional expression:
1)
t : Nat
─────────────
succ t : Nat
2)
t : Nat
─────────────
pred t : Nat
3)
t : Nat
───────────────
iszero t : Bool
4)
t1 : Bool, t2: T, t3: T
───────────────────────────
if t1 then t2 else t3 : T
5)
(λ x: T → y): T → Y, u: T, y: Y
────────────────────────────────
(λ x: T → y) u: Y
6)
t1: T → Y, t2: T
──────────────────
t1 t2: Y
1), 2) and 3) are quite similar. In 1) and 2) we declare that if we have an expression t of type Nat, then both pred t and succ t will be of type Nat. On the other hand, iszero accepts an argument of type Nat and results of type Bool.
4) states that the condition of the conditional expression should be of type Bool and the expressions in the then and else branches should be the of the same type T, where we can think of T as a generic type (placeholder which can be filled with any type, for instance Bool or Nat, even Nat → Bool).
Rule 5) states that if a function has type T → Y and is applied to argument u of type T then the result of the evaluation will be of type Y.
Finally, 6) states that if we have t1 of type T → Y and t2 of type T then t1 t2 will be of type Y.
It’s interesting to see how the type rules does not explain how to evaluate the individual expressions but only define a set of rules which the expressions should hold.
Developing the Compiler

Now from the formal definition of our programming language lets move to its actual implementation. In this section we will explain how the compiler’s implementation works. Here are the high-level steps of execution:
const program = readFileSync(fileName, { encoding: 'utf-8' });
const ast = parse(program);
const diagnostics = Check(ast).diagnostics;
if (diagnostics.length) {
console.error(red(diagnostics.join('\n')));
process.exit(1);
}
if (compile) {
result = CompileJS(ast);
console.log(result);
} else {
console.log(Eval(ast));
}
In the pseudo code above, we can notice that the program’s compilation & interpretation happen the following way:
- Read the file containing our program.
- Parse the source code and get an abstract syntax tree.
- Perform type checking with the
Checkfunction. - In case the type checker has found type errors, report the diagnostics.
- Either compile to JavaScript or evaluate the program.
It’s lovely to see a functional level of cohesion of the individual components! In the last next four sections we’ll explain steps 2-5.
Lexer & Parser
The implementation of a lexer and parser for this small language will be quite simple. We can use traditional recursive descent parsing algorithm for producing an Abstract Syntax Tree (AST).
For diversity, lets generate the modules for lexical and syntax analysis by using Peg.js grammar.
Here’s the grammar itself:
Program = _'('*_ a:Application _')'?_ {
return a;
}
Application = l:ExprAbs r:Application* {
if (!r || !r.length) {
return l;
} else {
r = r.pop();
return { type: 'application', left: l, right: r};
}
};
Abstraction = _ '('* _ 'λ' _ id:Identifier ':' t:Type '→' f:Application _ ')'? _ {
return { type: 'abstraction', arg: { type: t, id: id }, body: f };
}
Expr = IfThen / IsZeroCheck / ArithmeticOperation / Zero / True / False / Identifier / ParanExpression
ArithmeticOperation = o:Operator e:Application {
return { type: 'arithmetic', operator: o, expression: e };
};
Operator = Succ / Pred
IfThen = If expr:Application Then then:Application Else el:Application {
return { type: 'conditional_expression', condition: expr, then: then, el: el };
}
Type = Nat / Bool
_ = [ \t\r\n]*
__ = [ \t\r\n]+
Identifier = !ReservedWord _ id:[a-z]+ _ {
return { name: id.join(''), type: 'identifier' };
}
ParanExpression = _'('_ expr:Expr _')'_ {
return expr;
}
ReservedWord = If / Then / Else / Pred / Succ / Nat / Bool / IsZero / False
Succ = _'succ'_ {
return 'succ';
}
Nat = _'Nat'_ {
return 'Nat';
}
...
For simplicity I’ve omitted some implementation details. The entire grammar can be found here.
We’ll take a look at only few grammar rules. If you’re interested in the entire syntax of Peg.js, you can take a look at the official documentation and experiment on the online playground. If you’re interested into some theoretical background, I’d recommend you to find a read for BNF form.
Lets take a look at two interesting nonterminals from the grammar:
Application Nonterminal
Application = l:ExprAbs r:Application* {
if (!r || !r.length) {
return l;
} else {
r = r.pop();
return { type: 'application', left: l, right: r};
}
};
The application nonterminal (t t) from the “Syntax” section above can be expressed with this Peg rule. The semantics behind the rule is that, we can have one expression or abstraction followed by 0 or more other applications.
We name the left nonterminal l (l:ExprAbs) and the right one r (r:Application), after that, in case of a match, we return an object, which will be used as an AST node, with type abstraction, left and right branches.
Another interesting nonterminal is the abstraction:
Abstraction = _ '('? _ 'λ' _ id:Identifier ':' t:Type '→' f:Application _ ')'? _ {
return { type: 'abstraction', arg: { type: t, id: id }, body: f };
}
We can see that it starts with an optional opening parenthesis, after that we have the lambda (λ) symbol, followed by the parameter declaration and its type. After that, we have the hard to type arrow (→) and the abstraction’s body, which we try to match against the Application rule from above.
For instance, the AST of the program: (λ a: Bool → succ 0) iszero 0, after parsing, will look like:
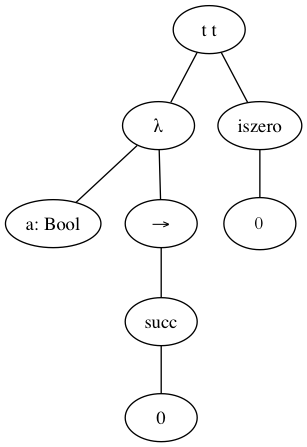
The root node is the application nonterminal (t1 t2), where t1 equals the abstraction (i.e. λ a: Bool → succ 0) and t2 the expression iszero 0.
Developing the Type Checker
Now lets take a look at the type checker. First, lets declare the set of primitive types:
const Types = {
Natural: 'Nat',
Boolean: 'Bool'
};

Function Type
We’ll express the function type using an array of types, for instance ['Bool', 'Nat'] is a function which accepts an argument of type Bool and returns Num. From the following example, we can see that our language supports high-order functions:
(
(λ a: Nat →
λ b: Nat → succ a)
0
) succ 0
The outermost function has type Nat → (Nat → Nat), which means that it accepts an argument of type Nat and returns a function of type Nat → Nat.
Type Checking Algorithm and Type Inference
The algorithm for performing type checking will traverse the AST and verify if each individual node has correct type according to the type rules from section “Type System”. Generally speaking, the algorithm will be just a JavaScript translation of the definitions in the “Type Rules” section from above.
Here are the basic rules that we will implement:
- Check if the condition of a conditional expression is of type
Bool. In order to do that, we need to invoke the algorithm recursively and find out the type of the expression passed as condition of the conditional expression (rule4)). - Check if both the branches of conditional expression have the same type. Here we need to recursively find the types of both sub-expressions and compare them (rule
4)). - Check if argument passed to a function is of the correct type. In this case we need to find the type of the expression passed as argument to the function and check if it matches with the declaration of the function (rule
5)). In order to find the type of the function we need to find the type of its body. This is called type inference. - Check if the arguments of the built-in functions are of the correct type. The procedure is quite similar to 3. (rules
1),2)and3)). - Check if the types of the left and right side of an application match. We need to find the types of both terms recursively, just like for all other cases above. For instance, if we have function of type
Nat → Bool, we can only apply it to an argument of typeNat(rule6)).
From above we can see that each point includes the word “check”, so it looks like, an important part of the type checking algorithm is the type comparison. Lets peek at its implementation:
Comparing Types
In order to compare two types and see if they are equivalent, we can use the following function:
const typeEq = (a, b) => {
if (a instanceof Array && b instanceof Array) {
if (a.length !== b.length) {
return false;
} else {
for (let i = 0; i < a.length; i += 1) {
if (!typeEq(a[i], b[i])) {
return false;
}
}
return true;
}
} else {
if (typeof a === 'string' && typeof b === 'string') {
return a === b;
}
}
return false;
};
The function first checks if both types are types of a function (i.e. have more than one type they are composed of). If that’s the case, we compare the types they are composed of one by one by invoking the typeEq function recursively. Otherwise, in case a and b are primitive types, we just compare them by their value (a === b).
Type Checking Implementation
Now we’re ready to take a look at the actual implementation of our type checker:
const Check = (ast, diagnostics) => {
diagnostics = diagnostics || [];
// By definition empty AST is correct
if (!ast) {
return {
diagnostics
};
}
...
// We get the type of identifier from the symbol table
} else if (ast.type === ASTNodes.Identifier) {
return {
diagnostics,
type: SymbolTable.lookup(ast.name)
};
// if-then-else block is correct if:
// - The condition is of type Boolean.
// - Then and else are of the same type.
} else if (ast.type === ASTNodes.Condition) {
if (!ast.then || !ast.el || !ast.condition) {
diagnostics.push('No condition of a conditional expression');
return {
diagnostics
};
}
const c = Check(ast.condition);
diagnostics = diagnostics.concat(c.diagnostics);
const conditionType = c.type;
if (!typeEq(conditionType, Types.Boolean)) {
diagnostics.push('Incorrect type of the condition of a conditional expression');
return {
diagnostics
};
}
const thenBranch = Check(ast.then);
diagnostics = diagnostics.concat(thenBranch.diagnostics);
const thenBranchType = thenBranch.type;
const elseBranch = Check(ast.el);
diagnostics = diagnostics.concat(elseBranch.diagnostics);
const elseBranchType = elseBranch.type;
if (typeEq(thenBranchType, elseBranchType)) {
return thenBranch;
} else {
diagnostics.push('Incorrect type of then/else branches');
return {
diagnostics
};
}
// The type of:
// e1: T1, e2: T2, e1 e2: T1
} else if (ast.type === ASTNodes.Application) {
const l = Check(ast.left);
const leftType = l.type || [];
diagnostics = diagnostics.concat(l.diagnostics);
const r = Check(ast.right);
const rightType = r.type || [];
diagnostics = diagnostics.concat(r.diagnostics);
if (leftType.length) {
if (!ast.right || leftType[0] === rightType) {
return {
diagnostics,
type: leftType[1]
};
} else {
diagnostics.push('Incorrect type of application');
return {
diagnostics
};
}
} else {
return { diagnostics };
}
}
return { diagnostics };
};
I have stripped some of the code since it’s not crucial for our purpose. If you’re interested in the complete implementation, you can find it here.
An interesting thing to notice is the continuation. We pass the diagnostics array to each invocation of the Check function. When we find a type error, we push a string representing a human readable message corresponding to the error in the array. This way, in the end of the invocation we have the list of all type errors found by the type checking algrithm.
If we go back to the entire compiler’s implementation:
...
const ast = parse(program);
const diagnostics = Check(ast).diagnostics;
if (diagnostics.length) {
console.error(red(diagnostics.join('\n')));
process.exit(`1)`;
}
...
In case the program that we want to type check is the following:
(λ a: Nat → succ succ 0) iszero true
The diagnostics that the compiler will produce will be as follows:
~/Projects/typed-calc master ❯ node index.js demo/incorrect1.lambda Evaluating "demo/incorrect1.lambda". Incorrect type of IsZero Incorrect type of application
Developing the Interpreter
Once the compiler goes through the phase of type checking there are a few options:
- Perform AST transformations in order to produce equivalent but more efficient AST for the purposes of the compiler’s back end.
- Skip the transformation phase and directly perform either code generation or evaluation.
In this section we’ll take a look at the interpreter which is going to evaluate our programs based on the AST produced by the parser (syntax analyzer).
Here’s its entire implementation:
const Eval = ast => {
// The empty program evaluates to null.
if (!ast) {
return null;
}
// The literals evaluate to their values.
if (ast.type === ASTNodes.Literal) {
return ast.value;
// The variables evaluate to the values
// that are bound to them in the SymbolTable.
} else if (ast.type === ASTNodes.Identifier) {
return SymbolTable.lookup(ast.name);
// if-then-else evaluates to the expression of the
// then clause if the condition is true, otherwise
// to the value of the else clause.
} else if (ast.type === ASTNodes.Condition) {
if (Eval(ast.condition)) {
return Eval(ast.then);
} else {
return Eval(ast.el);
}
// The abstraction creates a new context of execution
// and registers it's argument in the SymbolTable.
} else if (ast.type === ASTNodes.Abstraction) {
const scope = new Scope();
return x => {
scope.add(ast.arg.id.name, x);
SymbolTable.push(scope);
return Eval(ast.body);
};
// IsZero checks if the evaluated value of its
// expression equals `0`.
} else if (ast.type === ASTNodes.IsZero) {
return Eval(ast.expression) === 0;
// The arithmetic operations manipulate the value
// of their corresponding expressions:
// - `succ` adds 1.
// - `pred` subtracts 1.
} else if (ast.type === ASTNodes.Arithmetic) {
const op = ast.operator;
const val = Eval(ast.expression);
switch (op) {
case 'succ':
return val + 1;
case 'pred':
return (val - 1 >= 0) ? val - 1 : val;
}
// The application evaluates to:
// - Evaluation of the left expression.
// - Evaluation of the right expression.
// Application of the evaluation of the left expression over
// the evaluated right expression.
} else if (ast.type === ASTNodes.Application) {
const l = Eval(ast.left);
const r = Eval(ast.right);
return l(r);
}
return true;
};
The code is quite straightforward. It involves pre-order traversal of the produced AST and interpretation of the individual nodes. For instance, in case given node in the tree represents a conditional expression all we need to do is check its condition and return the result we get from the evaluation of its then or else branches, depending on the condition’s value:
if (Eval(ast.condition)) {
return Eval(ast.then);
} else {
return Eval(ast.el);
}
Developing a Code Generator
Here’s a list of the languages which compile to JavaScript. Why not create another language?

In fact, the transpilation (code generation) is going to be quite straightforward as well. The entire implementation of our “to JavaScript compiler” is on less than 40 lines of code. The entire transpiler can be found here`.
Let’s take a look at how we are going to translate application, abstraction and conditional expressions to JavaScript:
const CompileJS = ast => {
...
// Transpile a literal
if (ast.type === ASTNodes.Literal) {
return ast.value;
// Transpile identifier
} else if (ast.type === ASTNodes.Identifier) {
return ast.name;
// Transpile a conditional expression
} else if (ast.type === ASTNodes.Condition) {
const targetCondition = CompileJS(ast.condition);
const targetThen = CompileJS(ast.then);
const targetElse = CompileJS(ast.el);
return `${targetCondition} ? ${targetThen} : ${targetElse}\n`;
// Transpile an abstraction
} else if (ast.type === ASTNodes.Abstraction) {
return `(${ast.arg.id.name} => {
return ${CompileJS(ast.body)}
})`;
// Transpile an application
} else if (ast.type === ASTNodes.Application) {
const l = CompileJS(ast.left);
const r = CompileJS(ast.right);
return `${l}(${r})\n`;
} else {
return '';
}
};
Notice that when the current node is a literal (i.e. 0, true or false) we return its value. In case we transpile a conditional expression, we first transpile its condition, then its then expression, right after that its else expression and finally, the entire conditional expression itself. The result will be a JavaScript ternary operator.
Right after that is the source code for transpilation of a function (or abstraction, the way we call a function in our definitions above). The source code is quite straightforward, we declare the function’s argument based on the argument of our lambda and after that compile function’s body and place it as the return statement.
Finally, we transpile the application. For this purpose, we transpile the left sub-expression of the application which is supposed to be a function and apply it to the right hand side of the application.
Now if we transpile the following program to JavaScript:
(
λ x: Nat →
(λ y: Nat → x) 0
)
succ (
λ f: Nat →
(λ g: Nat → g) 0
) 0
We will get:
(x => {
return (y => {
return x;
})(0);
})(
(f => {
return (g => {
return g;
})(0);
})(0) + 1
);
Conclusion
The purpose of this article was to explain a “full-stack” process of design and development of a programming language. The explained language is an extension of the lambda calculus. On top of the primitives provided by the lambda calculus we added three built-in functions, natural numbers, boolean values, a syntax for conditional expressions and a type system. We provided a formal definition of these primitives in terms of small-step semantics and also defined a type system by using a series of type rules.
It’s interesting how straightforward is the JavaScript implementation which we directly derived from the mathematical definitions. We just “translated the math” into source code. Of course, the process of designing the source code has it’s own portion of creativity involved but the general algorithm is equivalent.
Another interesting observation is how similar are the algorithms for interpretation and type checking. With the type checking algorithm we performed type inference which was quite similar to the actual source code evaluation. Although with our basic type system this similarity still can be noticed, in case of dependent types the boundary between evaluation and type checking becomes even blurrier.
Where to go from here?

A natural direction for further development of the language will be to extend its syntax and type system. In this case, there should be put some effort in improving the language’s ergonomics. There are a few programming languages inspired by the lambda calculus and there are two main “syntactic camps” that they are in. For instance, the LISP-like languages can be distinguished by their intensive use of parentheses. On the other hand, the Haskell-like syntax often looks cleaner and has its own adoptions in languages like Elm.
Another direction for improvement is a better error reporting. With the grammar produced by Peg.js we can easy get the exact position in the program of the individual symbols. This will allow us to throw errors at specific locations which will make debugging much easier.
Will be happy to get your thoughts and observations from the article in the comments section below.