LLM-first Web Framework
Edit · Apr 19, 2025 · 5 minutes read · Follow @mgechev
Over the past few weeks I’ve been thinking about how we can make a framework easier for AI. In particular I’ve been only focused on building user interface. When we add a backend, database, and communication protocol across the backend and the frontend, we get another set of problems that could be a good fit for another post and exploration.
Looking at the current landscape of platforms for “vibe coding” I see two main problems:
- Mismatch of API versions. Often the LLM will generate code that uses deprecated or missing APIs from previous versions. I see that across the board with all frameworks since they all use versions and deprecate APIs.
- Lack of substantial training data. If you’re using a framework that’s not as popular or has new APIs that the LLM is not familiar with yet, you will likely get a dissatisfactory output. Frameworks such as Angular and React often are not too impacted here due to abundance of training data. You can still see this manifest for new APIs that are not widely used and documented yet.
There are a variety of solutions to these problems. For example:
- We can use the context window to provide relevant examples of the latest APIs
- We can also use RAG to augment the output with the latest documentation
- If we have money redundancy…we can fine-tune the model
I decided to solve these problems by building a framework!
Design decisions
The LLM-first framework I created has the following design:
- Minimal versus expressive syntax. It has orthogonal APIs that complement each other and there’s a single way of doing things. This could potentially make building apps with it more verbose, but there’s less for the LLM to “learn” and “know.”
- Familiar versus novel. Decided to use very basic syntax, hoping to leverage the LLM’s preexisting training data. For example, templating uses JavaScript object literals. There are a lot of them on GitHub and they have structural similarity to JSON.
- Fine-grained reactivity. Why not enable generation of fast apps by default!
I based this LLM-first framework on Revolt with one major change - the framework gets all text node and attribute values by invoking a getter function. This way, the framework accesses reactive and static values in the same way.
For example instead of specifying the value of the text node and the style attribute as text values, I’d use functions.
const HelloWorld = () => {
return {
name: "div",
children: () => "Hello, World!",
attributes: {
style: () => "color: red;"
}
};
};
This makes it easier for the LLM to produce working code. It doesn’t have to “understand” the difference between a static and reactive value.
Revolt LLM
I had a few spare hours and built a “vibe coding” platform that generates Revolt apps.
You can find the source code on GitHub.
Here’s a quick demo video:
The first (and only) draft of the system prompt I came up with:
You are a senior web developer who is expert in using signals in JavaScript. Create an application
based on a user prompt. For the purpose, use the framework and the examples of apps implemented in
this framework below:
// Framework implementation
// A couple of basic component examples
// Todo example, intentionally skipped
// Tetris example, intentionally skipped
Output the application as syntactically correct and executable JavaScript and will render the app on the screen.
All the styles of the application should be inlined under the style attribute of each element.
Use a dark theme for all the applications you generate.
Give your output in the format:
<revolt-response>
<revolt-explanation>
Explanation in up to 3 sentences and without any newlines
</revolt-explanation>
<revolt-code>
The code
</revolt-code>
</revolt-response>
For example:
<revolt-response>
<revolt-explanation>
Here is a simple hello world app
</revolt-explanation>
<revolt-code>
const HelloWorld = () => {
return {
name: "div",
children: () => "Hello, World!",
attributes: {
style: () => "color: red;"
}
};
};
render(HelloWorld(), document.body);
</revolt-code>
</revolt-response>
All future prompts will be from the user in the format:
User prompt: <prompt>
In Revolt LLM, I decided to keep chat history for the past two prompts and responses to provide a little extra context to the LLM. This works well for flows such as:
> User: Create a todo app
> LLM: [output]
> User: Change the color of the delete button to red
> LLM: [output]
In the example above, in addition to the “Change the color…” prompt, the LLM will also receive the previous prompt and output it produced.
Revolt as an IR
Another potential path forward is to use Revolt as an intermediate representation to generate code that uses a general purpose framework such as Angular or React. Technologies like mitosis use a similar technique for other use cases.
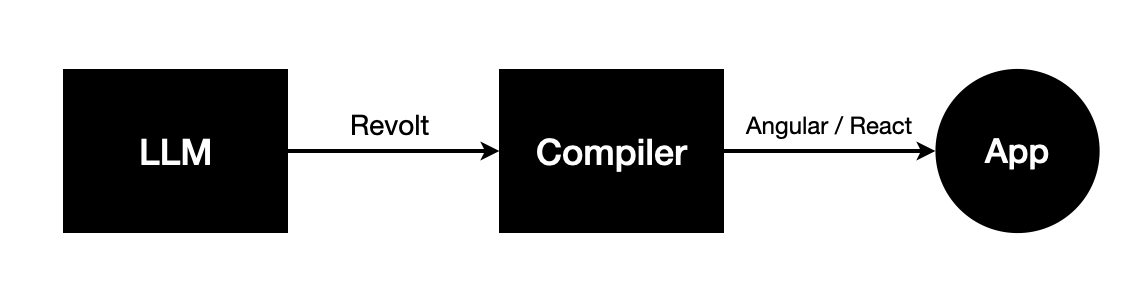
Revolt as an IR
This way we get the benefit of avoiding version skew since we pass Revolt in the context window. At the same time, the final output is code that uses a general purpose framework. In the compiler that transforms Revolt to Angular/React, we can hardcode rules that ensure the output uses the latest general purpose framework APIs.
Generating code that uses a general purpose framework allows developers to debug a technology they are familiar with and get a better interop with the corresponding framework ecosystem.
Moving forward
The three different approaches we discussed are:
- Augment the model by passing examples to ensure we generate working code using latest APIs
- Instead of using a general purpose framework, use Revolt and pass it in the context window
- Generate Revolt code and transform it to a general purpose framework via a deterministic compiler
All the three approaches have their trade-offs. I can definitely see a future in which an entire product will be based on a LLM-first framework and will provide a component model, together with integrations with other platforms.
In the short-term, I see how tools will primarily use the first approach and fallback to the third one in case of highly personalized user interface.