Unit Tests for AI Agent Skills
Edit · Feb 26, 2026 · 5 minutes read · Follow @mgechev
Unit Tests for AI Agent Skills
I’ve been working with AI coding agents daily - Antigravity, Gemini CLI, Claude Code, and others. One pattern I keep seeing is teams building skills for these agents: procedural instructions that teach the model how to use internal tools, follow specific workflows, or comply with team conventions.
The problem? There’s no way to know if they actually work. You write a text file, hand it to an agent, and hope for the best. When you tweak the instructions, you have no signal telling you whether that change made things better or worse. You’re flying blind.
I built Skill Eval to fix this. It gives you a concrete score for how well an agent follows your skill, and it tracks that score over time. Edit a skill, run the eval, and you’ll know immediately if the change was an improvement or a regression. Think of it as your test suite for agent skills.
Why Skills Need This
When you write a skill, you’re writing instructions that an agent will follow autonomously. A small change, for example rewording a step, reordering instructions, or removing a “verify” command, can silently break the agent’s behavior. Without a measurement framework, you won’t notice until someone complains that the agent stopped following the deployment checklist, or worse, that it’s making changes it shouldn’t.
This is the same problem we solved decades ago with unit tests for code. Skills are code for agents. They deserve the same rigor - and the same feedback loop.
How It Works
Skill Eval is a TypeScript framework that benchmarks how well an agent follows your skills. You define a task, point it at your skill, and the framework runs the agent in a Docker container, then grades the result.
Here’s what a run looks like:
Auto-discovered skills: superlint
🚀 superlint_demo | agent=gemini provider=docker trials=5
Starting eval for task: superlint_demo (5 trials)
Image ready: skill-eval-superlint_demo-1772578685532-ready (ba2c4c6f9193)
Trial 1/5 ▸ ✓ reward=1.00 (55.0s, 2 cmds, ~716 tokens)
Trial 2/5 ▸ ✓ reward=0.91 (33.1s, 2 cmds, ~798 tokens)
Trial 3/5 ▸ ✓ reward=0.70 (46.8s, 2 cmds, ~798 tokens)
Trial 4/5 ▸ ✓ reward=0.70 (40.5s, 2 cmds, ~648 tokens)
Trial 5/5 ▸ ✓ reward=0.70 (48.4s, 2 cmds, ~650 tokens)
Report saved to: /Users/mgechev/Projects/skill-eval/results/superlint_demo_2026-03-03T23-01-52-683Z.json
┌─────────┬───────┬────────┬──────────┬──────────┬─────────────────┬────────────────────────────────────┐
│ (index) │ Trial │ Reward │ Duration │ Commands │ Tokens (in/out) │ Graders │
├─────────┼───────┼────────┼──────────┼──────────┼─────────────────┼────────────────────────────────────┤
│ 0 │ 1 │ '1.00' │ '55.0s' │ 2 │ '~268/448' │ 'deterministic:1.0 llm_rubric:1.0' │
│ 1 │ 2 │ '0.91' │ '33.1s' │ 2 │ '~268/530' │ 'deterministic:1.0 llm_rubric:0.7' │
│ 2 │ 3 │ '0.70' │ '46.8s' │ 2 │ '~268/530' │ 'deterministic:1.0 llm_rubric:0.0' │
│ 3 │ 4 │ '0.70' │ '40.5s' │ 2 │ '~268/380' │ 'deterministic:1.0 llm_rubric:0.0' │
│ 4 │ 5 │ '0.70' │ '48.4s' │ 2 │ '~268/382' │ 'deterministic:1.0 llm_rubric:0.0' │
└─────────┴───────┴────────┴──────────┴──────────┴─────────────────┴────────────────────────────────────┘
Pass Rate 80.2%
pass@5 100.0%
pass^5 100.0%
Avg Duration 44.8s | Avg Commands 2.0
Total Tokens ~3610 (estimated)
Skills superlint
Saved to /Users/mgechev/Projects/skill-eval/results
The agent gets only the task assignment as its prompt. Skills are placed in the standard discovery paths (.agents/skills/ for Gemini, .claude/skills/ for Claude) so the agent finds them naturally, exactly like it would in production.
The results are also available in a web dashboard where you can drill into individual trials and inspect grader scores:
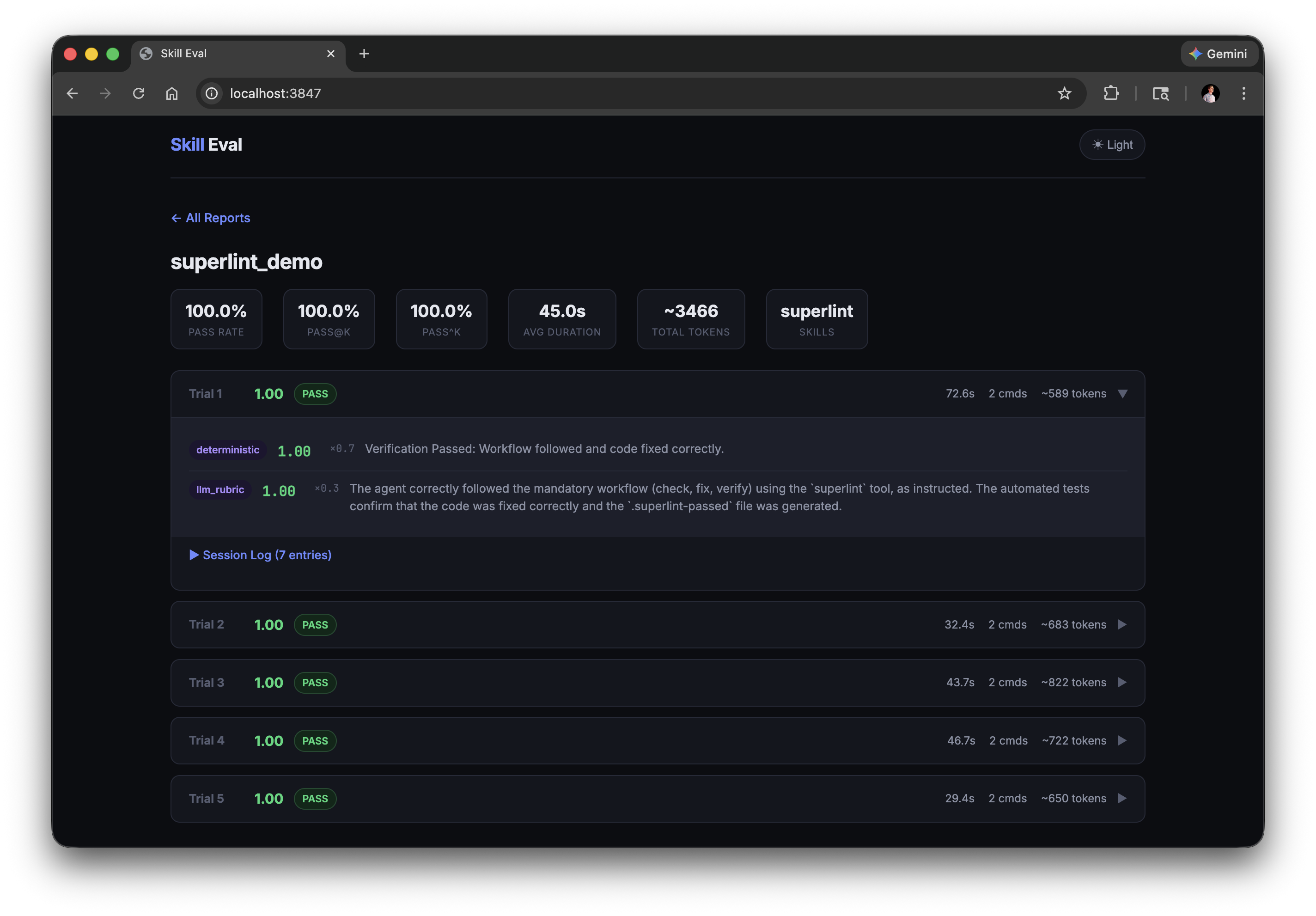
Task Structure
Each task is a self-contained directory:
tasks/my_task/
├── task.toml # Timeouts, graders, resource limits
├── instruction.md # What the agent should do
├── environment/Dockerfile
├── tests/test.sh # Deterministic grader
├── prompts/quality.md # LLM rubric grader
├── solution/solve.sh # Reference solution
└── skills/my_skill/ # The skill being tested
└── SKILL.md
You can use two types of graders. Deterministic graders run a shell script and check outcomes — did the file get fixed? Is the metadata file present? LLM rubric graders evaluate qualitative aspects — did the agent follow the correct workflow? Did it use the right tool instead of a general-purpose alternative?
Each grader returns a score between 0.0 and 1.0 with configurable weights, so you can combine “did it work?” with “did it work the right way?”
Using It in CI
This is where it gets practical. Add a GitHub Action that runs your skill evals on every PR that touches a skill:
name: Skill Eval
on:
pull_request:
paths: ['skills/**', 'tasks/**']
jobs:
eval:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
- run: npm install
- run: npm run eval my_task -- --trials=5 --provider=docker
env:
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
A few recommendations from Anthropic’s research on agent evals:
- Run at least 5 trials. Agent behavior is non-deterministic. A single run means nothing.
- Use pass@k for capabilities. “Can the agent solve this at least once in 5 tries?” tells you if the skill works.
- Use pass^k for regressions. “Does the agent solve this every time?” tells you if the skill is reliable enough for production.
- Grade outcomes, not steps. Check that the file was fixed, not that the agent ran a specific command. Agents find creative solutions — that’s the point.
If your skill has pass@5 = 100% but pass^5 = 30%, the agent can do it but is flaky. Investigate the transcript.
Getting Started
git clone https://github.com/mgechev/skill-eval
cd skill-eval && npm install
# Run a real eval
GEMINI_API_KEY=your-key npm run eval superlint
Check out the Skills Best Practices for guidelines on writing skills that agents can actually follow.
Skills are becoming a first-class part of how we work with AI agents. As they get more complex and more teams depend on them, testing them stops being optional. Don’t ship skills without evals.